
Da un recente articolo di Ympronta: “Cosa pensano gli umani delle macchine che pensano? Applicazioni di IA nel farmaceutico” (1ª Parte)
L’Intelligenza Artificiale è entrata a far parte della nostra realtà ormai da diversi anni. Ognuno di noi ne viene a contatto ogni giorno, in maniera più o meno consapevole. Ma ammettiamolo, comprendiamo molto vagamente come l’IA funziona veramente. Certo, possiamo vivere tranquillamente anche senza questa conoscenza, cogliendo semplicemente i frutti e i vantaggi offerti dall’IA.
Ma dato che l’IA è uno dei componenti principali della quarta rivoluzione industriale e dato che questa pervade tutti gli aspetti delle nostre vite, capire almeno i principi fondamentali può essere un vantaggio non indifferente per ognuno. Specialmente nell’ambito lavorativo, dove prima o poi, in un modo o nell’altro toccherà a tutti dover sfruttare questi strumenti.
In questo articolo racconteremo, in termini semplici ma concreti, che cos’è l’Intelligenza Artificiale e in questa prima parte parleremo dei concetti teorici e dei problemi tipici che l’IA può aiutarci a risolvere. Nel prossimo articolo vedremo quali possono essere le applicazioni concrete dell’IA nell’industria farmaceutica.
NON C’È NULLA DI MISTICO NELL’IA

Eppure, questo termine incute timore in molte persone. Forse perché pensiamo che creare qualcosa di intelligente non ci è permesso e, facendolo, rischiamo di scatenare l’ira degli dèi, prima ancora di essere sopraffatti dalla nostra stessa creatura.
Ma abbandoniamo questi dubbi filosofici per entrare nel merito della questione.
L’automazione industriale, nata probabilmente con i primi mulini a vento, è quell’ambito scientifico che prevede l’utilizzo dei mezzi tecnologici e metodi matematici per liberare l’uomo dal lavoro meccanico.
Ma, se parliamo di attività di routine, la domanda nasce spontanea: a che ci servono tutte queste macchine intelligenti? Perché non possiamo semplicemente ricondurre tutte le attività a degli algoritmi di base, procedure standard, semplici sequenze di azioni? Certo, in caso di processi semplici, come il cleaning di una linea, le azioni sono poche, diciamo una decina. Ma nel caso di qualcosa di complesso come l’intera produzione dei farmaci, le variabili in gioco da gestire diventano centinaia o migliaia.
E perché questo diventa un problema, specialmente con la potenza di calcolo disponibile oggi?
Infatti, questo sarebbe anche possibile, ma quanto meno poco universale. Supponiamo che nel processo è comparsa una deviazione dal percorso standard (una normalità nel Pharma). All’istante compariranno migliaia di nuovi parametri da considerare. Non solo. A volte i processi reali sono talmente complessi che non è nemmeno chiaro quale può essere l’algoritmo che lo rappresenta.
 Anche la definizione dell’obiettivo in questo caso è completamente differente: ci sono tanti dati, le relazioni tra questi dati non sono chiare ed è necessario un algoritmo che permette proprio di rilevare queste relazioni. Ed è qui che possiamo fare l’analogia tra il cervello umano e le reti neurali, ma non per il ragionamento, bensì per l’apprendimento.
Anche la definizione dell’obiettivo in questo caso è completamente differente: ci sono tanti dati, le relazioni tra questi dati non sono chiare ed è necessario un algoritmo che permette proprio di rilevare queste relazioni. Ed è qui che possiamo fare l’analogia tra il cervello umano e le reti neurali, ma non per il ragionamento, bensì per l’apprendimento.
Già, il vero focus è proprio sul nostro modo di imparare: con tanti esempi, con tanti tentativi ed errori. Quando non riusciamo la prima volta, ci viene mostrato qual è il risultato corretto. E questa analogia estremamente umana…funziona! Le auto a guida autonoma, le previsioni meteo, la compravendita delle azioni in borsa, e tanto altro. Sono tutti esempi di problemi complessi, non standard e non banali, nei quali già oggi viene fatto uso massiccio dell’intelligenza artificiale per prendere le decisioni.
Cerchiamo di capire come inizia questo processo e come possiamo istruire una macchina.
 Nel Machine Learning (apprendimento automatico, o meglio insegnare alle macchine) abbiamo bisogno di tre principali componenti:
Nel Machine Learning (apprendimento automatico, o meglio insegnare alle macchine) abbiamo bisogno di tre principali componenti:
- Dati
- Caratteristiche
- Algoritmi
DATI
Vogliamo riconoscere i gatti? Ci servono immagini dei gatti. Vogliamo riconoscere le e-mail spam? Abbiamo bisogno degli esempi di spam. Vogliamo comprendere gli interessi delle persone? Dobbiamo analizzare i loro like, commenti e condivisioni. E di questi esempi ne abbiamo bisogno tantissimi. Decine di migliaia sarebbe il minimo indispensabile.
I like, il tempo di visualizzazione dei video, i commenti, e così via, sono tutti degli indicatori d’interesse che verranno usati dagli algoritmi di ML per predire quali contenuti saranno di vostro interesse.

Ma come si fa a raccogliere i dati? Qualcuno lo fa in maniera diretta (dopo averci fatto accettare le condizioni di servizio che prevedono la raccolta dei nostri dati). Qualcuno fa il furbo e ci sfrutta come manodopera gratuita. Basta pensare a quando dobbiamo indicare le immagini che contengono una barca, una bici o un semaforo per dimostrare di non essere dei robot. Congratulazioni, in quel momento avete insegnato qualcosa di nuovo ad una macchina. Grazie Google.
In questo modo hanno digitalizzato le uscite cartacee di New York Times, e di tantissimi libri, che sono tutti disponibili su Google Book Search. Qualcuno vede in questo un atto nobile, qualcuno intravede un parassitismo nascosto. Ma è chiara una cosa fondamentale: senza grandi quantitativi di dati puliti, detti Dataset o Row Data, non può esistere l’Intelligenza Artificiale.
CARATTERISTICHE
Dette anche proprietà, o features, o segni, o…caratteristiche. Può essere qualsiasi cosa. Il modello dell’auto, il sesso dell’utente, il prezzo delle azioni, la frequenza di utilizzo di un termine specifico (per esempio “Ympronta”). Per la macchina è molto importante sapere su cosa deve focalizzarsi.
È comodo quando i dati sono già in forma tabellare. In questo caso i nomi delle colonne sono proprio delle caratteristiche. Facendo così abbiamo facilitato la vita alla nostra macchina. Questo approccio viene chiamato “Apprendimento Supervisionato“ (o apprendimento con l’insegnante). L’insegnante ha già definito tutte le caratteristiche dei gatti e dei cani, indica le immagini contenenti i gatti e quelle con i cani, e la macchina apprende.
Ma ci sono situazioni in cui alla macchina viene fornita una montagna di foto con gatti e cani, e povera macchina prova da sola a trovare le somiglianze e le differenze. Questo approccio si chiama “Apprendimento NON Supervisionato” (senza insegnante). In questo caso la sola ricerca delle caratteristiche richiede molto più tempo che il resto dell’apprendimento. E non c’è nemmeno la garanzia che il risultato finale sarà soddisfacente.
In questo cominciamo ad intravedere il principale problema dell’intelligenza artificiale, ovvero della sua maturità al giorno d’oggi. Un algoritmo “addestrato” con successo su uno specifico Dataset può essere inutile se applicato sui dati completamente nuovi. Ma è anche vero che è dall’apprendimento non supervisionato che possiamo trarre dei vantaggi maggiori. Basta pensare ai casi, sempre più frequenti, quando la macchina individua delle caratteristiche e delle relazioni che un umano non potrebbe mai vedere, o addirittura non le comprende nemmeno di fronte all’evidenza.
ALGORITMI
Tutti i compiti che possono essere svolti dalle macchine possono essere raggruppati in tre principali tipi:
- Classificazione
- Regressione
- Clustering
Classificazione
Calzini in base al colore, clienti in base al paese, musica in base al genere, cani in base alla razza, e così via. Classificazione è il compito più diffuso in tutto il Machine Learning. E la macchina si comporta qui come un bambino che deve ordinare la stanzetta: le bambole in una cassa, i robot nell’altra.
| E se dovesse capitare una bambola-robot? |
Questo è il momento giusto per restituire un errore.
Regressione
 Di fatto è come la classificazione con la differenza che dobbiamo predire un valore. Costo dell’auto usata in base al chilometraggio, durata del percorso stradale in base all’ora, valore delle azioni dell’azienda in base al tweet del suo CEO.
Di fatto è come la classificazione con la differenza che dobbiamo predire un valore. Costo dell’auto usata in base al chilometraggio, durata del percorso stradale in base all’ora, valore delle azioni dell’azienda in base al tweet del suo CEO.
In sostanza in questo tipo di problemi ricade qualsiasi necessità di disegnare un grafico, una curva che rappresenta il valore di qualcosa in base a qualcos’altro. Chiunque può farlo, basta una lavagna e un pennarello. Ma la macchina lo farà con una precisione matematica.
Clustering
Come la classificazione ma senza conoscere a priori le classi. La macchina da sola cerca gli oggetti simili e li raggruppa nei cluster. Come dicevamo, questo è il compito più difficile ma anche più straordinario poiché, non solo la macchina è in grado di elaborare enormi quantitativi di dati, ma può trovare delle relazioni “nascoste” che noi umani non possiamo nemmeno immaginare. Eppure, ci sono. Estremizzando possiamo chiamare questo tipo di problemi “Effetto Farfalla”, quando l’algoritmo riesce ad analizzare milioni di eventi apparentemente indipendenti tra loro e alla fine individua una relazione causa-effetto nei due avvenimenti distanti tra loro, sia fisicamente che sull’asse temporale.
CONCLUSIONI
Abbiamo, dunque, chiarito i tre pilastri del Machine Learning ed ora diamo delle definizioni importantissime che vi aiuteranno a non fare brutte figure con gli esperti, facendo domande del tipo “potrebbe Machine Learning sostituire l’Intelligenza Artificiale”.
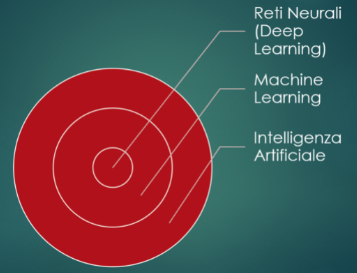
L’intelligenza Artificiale è il nome dell’intero ambito scientifico. Machine Learning è un sottoinsieme dell’Intelligenza Artificiale. Reti Neurali è uno dei tipi di Machine Learning.
Le reti neurali sono in grado di risolvere gli stessi problemi che gli altri algoritmi del Machine Learning. Ma la loro peculiarità, e qui ricordiamo l’analogia con il cervello umano fatta all’inizio dell’articolo, è la capacità di auto-apprendimento, capacità di agire in base alle esperienze precedenti, diminuendo di volta in volta il numero degli errori. Proprio questo è il motivo della loro attuale popolarità.
E, dunque, siamo entrati in un’era di macchine intelligenti, che pensano razionalmente? Non ancora. Gli esperti affermano che al giorno d’oggi l’intelligenza artificiale è debole. E questa non è una metafora, bensì un criterio di valutazione del livello di intelligenza delle macchine. Esiste, infatti, una suddivisione dell’IA in “forte” e “debole”.
IA Debole: si intende la capacità dei computer di risolvere problemi informatici del tipo riconoscimento degli oggetti, o tradurre la voce umana in testo scritto.
IA Forte, invece, presuppone che il computer non solo riesce ad elaborare le informazioni, ma ne comprende anche il significato.

Anche se l’IA fa passi da gigante, si tratta ancora dell’IA debole. Quando comparirà l’IA Forte? Difficile dirlo, anche perché questo dipende direttamente dalla nostra comprensione del funzionamento del nostro cervello, cosa ancora lontana dall’essere completa. Ma ovviamente la ricerca in questa direzione viaggia a pieno ritmo e il giorno che creeranno una vera IA Forte, dovremo porci due domande importanti:
- Cosa pensano gli umani delle macchine che pensano?
- Cosa pensano le macchine degli umani che pensano?
Nel prossimo articolo vedremo come possiamo sfruttare le potenzialità dell’Intelligenza Artificiale per risolvere i problemi, sia quelli classici che quelli più recenti, del mondo dell’industria farmaceutica.
Visita il sito di Ympronta per saperne di più




